한글 인코딩 관련 간단 정리
안녕하세요. NHN엔터테인먼트 정성환입니다.
그동한 문자셋과 인코딩과의 관계를 정리한 내용을 공유드립니다.궁금하신분께 많은 도움이 되었으면 좋겠습니다.
문자셋과 인코딩 방법의 관계에 대하여 명료화하자면, 문자셋(Character set)은 문자 코드 집합, 인코딩 방법은 그것을 어떻게 표현할지에 관한 것입니다. 서로 다른 개념이기는하나 인코딩 방법은 문자셋에 종속적입니다.
1. ksc5601과 cp949
ksc5601, cp949은 문자셋이기는하나, 각각 조금은 다른 인코딩 방법을 가지고 있습니다.
그래서 문자셋이나 인코딩 방법을 따로 구분해서 부르기 힘들고, 각각 통칭하여 EUC-KR과 cp949(혹은 EUC-KR 확장)이라고 불리웁니다.
ksc5601은 92년도에 국가에서 정의한 표준으로 2바이트를 사용하고 2,350자의 한글을 표현 가능합니다.
cp949는 윈도95에 마이크로소프트가 독자적으로 제정한 규격으로 11,172자의 한글을 표현 가능합니다. 인코딩은 확장된 euc-kr이라고 할 수 있으며 기존의 euc-kr에 추가적으로 지원하는 문자셋을 덧붙인 형태입니다.
이런 연유로 euc_kr이라고 표기되는 문자셋/인코딩이 애매하고 헷갈리게 되어버리는 겁니다. 대충 windows, linux, java, web 월드에서 정리하면 다음과 같습니다.
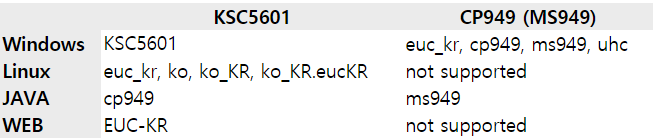
간혹가다가 html 문서에 charset=cp949 등으로 지정된 웹페이지가 있기는 한데, 이것은 엄연히 표준을 위반한 것입니다.
W3C에서는 IANA에서 공인된 문자셋만을 표준으로 하고 있는데 거기에 CP949 혹은 MS949는 포함되지 않습니다.
(그리고 자바는 왜 cp949가 ksc5601을 나타내는지 잘 모르겠습니다. -_-;; 위키에도 cp949는 ms 규격이라고 나와있는데 말이죠...)
2. 유니코드
유니코드는 문자셋(Character Set)인 UCS(Universal Character Set)과 그 인코딩 방법(유니코드 인코딩)들의 통칭입니다. 인코딩 방법은 흔히들 알고 있는 UTF-8, UTF-16, UTF-32 입니다.
유니코드의 한글은 우리가 알고 있던 완성형 형태의 코드와, 초성/중성/종성으로 나누어진 코드를 모두 가지고 있습니다.그리고 완성형 형태의 코드도, 초성을 z축으로, 중성을 x축으로, 종성을 y축으로 구성하여, 코드 하나에 대해 간단한 산술연산으로 초성/중성/종성으로 분리해낼 수 있습니다.
cp949는 마이크로소프트가 제맘대로 만든터라, 코드의 배열이 정말..... 제 멋대로 입니다. 이게 무슨 문제를 초래하냐면... sorting 이 엉망으로 된다는 얘기지요.. euc-kr 즉 ksc5601은 그래도 우리 어순대로 코드가 배열되어 있어서 여기에 속한 문자들은 올바르게 sorting됩니다. 그래서 모든 사람들이 cp949를 사용하던 시절에는 이러한 sorting 문제가 선배 개발자들을 괴롭혔었죠.
아까 완성형 형태의 코드와 초성/중성/종성 코드가 분리되어있다고 소개했는데, 그것 때문에 또 약간의 문제가 있습니다.그럼 한글을 표현할때 어떤 방법으로 하는가...인데요. 쉽게 말하면 완성형으로 표현할 것인가, 조합형으로 표현할 것인가...입니다.
대부분의 platform world에서는 완성형 형태의 코드를 사용합니다. 그것을 NFC라고 합니다.(개념은 복잡하고 이해할 필요는 없을 것 같아 생략하겠습니다.) 초성/중성/종성으로 구분된 코드를 조합하여 한글을 표현하는 방법을 NFD라고 하는데, 거의 맥/iOS의 파일 시스템에서만 유일하게 사용됩니다.
그래서 제대로 transcoding 해주지 않는 전송 프로그램이나 압축 프로그램을 사용하여 맥에서 윈도로 파일을 전송하는 경우 한글이 풀리는 문제가 있습니다.
여기에 보너스로 문제를 발생시키는 또 하나의 요인을 소개하자면....
BOM(Byte Order Mark)이라는 것입니다. 이것은 바이트 스트림의 특정 부분에 삽입되는 3바이트의 마크로,
이후 문서의 끝까지 혹은 다음 BOM까지는 이 유니코드 인코딩을 사용하겠다.. 라고 명시합니다.
그런데, 기본적으로 UTF-8을 사용하는 리눅스/맥에서는 이 BOM을 생략합니다. 즉, 문서 저장시 파일의 어느 부분에도 BOM이 포함되지 않습니다.
윈도는 기본적으로 유니코드로 파일을 저장할 때 BOM을 파일의 첫머리에 넣어둡니다. (explorer에서 파일에 오른쪽 버튼을 눌러 상세정보에 들어가면 BOM을 제거할 수 있는 방법이 있습니다.)
그래서 이러한 처리를 제대로 못하는 앱으로 윈도에서 저장된 유니코드 파일을 리눅스/맥에서 읽으면 역시 엉망으로 읽힙니다.
글을 쓰다보니 길어졌는데, 결론은 영어를 사용하지 않는 변방의 서러움으로 귀결되는 것 같습니다.
크로스 플랫폼 앱을 만들때 누구나 겪는 문제일텐데.... 왜냐면 또 이것 말고도 괴롭게 하는 요소들이 또 너무 많거든요... -_-;; 예를 들어 NTFS는 UTF-16으로 인코딩 하고요... zip 파일은 인코딩 표준 방법을 명시하지 않습니다. 즉, 각각 앱 혹은 OS마다 멋대로 넣어버린다는 거죠...
휴... 암튼 참고용, 혹은 스스로 참조용으로 정리해봤습니다. (언젠가는..) 도움이 되셨으면 좋겠습니다.
감사합니다.
[출처] http://meetup.cloud.toast.com/posts/35
 몰래 염탐 가능한 삼성의 갤럭시 S6/엣지/노트4
몰래 염탐 가능한 삼성의 갤럭시 S6/엣지/노트4